Most agent workflows are running at the autonomy level that was easiest to implement. Not the one that reflects actual risk. That’s not a governance model. That’s a default.
The Autonomy Nobody Decided
Here’s a question worth asking in your next planning meeting: who decided how autonomous your AI agents are?
Not who deployed them. Not who wrote the prompts. Who decided which actions they’re allowed to take without a human approving them first? It’s one of the ten questions every leader should be asking right now, and in most organizations it doesn’t have a clean answer.
In most organizations, the honest answer is nobody. The autonomy level wasn’t a decision. It was the path of least resistance at deployment time. Someone needed to ship, the default was full autonomy, and nothing has changed since.
The failure mode isn’t too much autonomy or too little. It’s that nobody made the call deliberately. Full autonomy applied to the wrong action type is how you get runaway costs, unauthorized data access, and outcomes nobody can explain after the fact. Restrictive human-in-the-loop applied to low-risk actions is how you get bottlenecks that kill adoption before the technology gets a fair shot. Both are symptoms of the same problem. We covered why human-in-the-loop is a control layer, not a bottleneck in Part 1. This is where that argument gets operational.
The question isn’t whether AI agents should act autonomously. They should… for the right things. The question is whether anyone in your organization has decided which things those are.
Two Things You Have to Think About Simultaneously
Most autonomy decisions are made on one dimension when they should be made on two.
The first is what kind of work the agent is actually doing. Some agent actions are deterministic… move this record, apply this rule, follow this script. The logic is clear, the output is predictable, and a human reviewing every instance is usually just slowing things down. Other actions require genuine judgment… interpreting ambiguous data where the right answer isn’t obvious, making a call where the policy runs out, prioritizing among competing considerations that the rules don’t fully cover. Those aren’t the same category and shouldn’t be treated the same way.
The second is what happens when it gets it wrong. An agent that misfires on a low-stakes action creates noise. An agent that misfires on a high-stakes action creates an incident. A workflow that executes a rule incorrectly once is a bug. A workflow that executes that rule incorrectly ten thousand times before anyone notices is a liability. The Anthropic billing change earlier this month is a clean example of this: agents running at full autonomy with no cost classification, no threshold that triggered a review. The risk dimension was never part of the autonomy decision.
Most organizations think about one of these dimensions and miss the other. “This action is deterministic so we automated it.” Fair enough… but what’s the cost if the deterministic logic is wrong at scale? “This requires judgment so we put a human in the loop.” But is the human reviewing every action, or just the ones that actually matter?
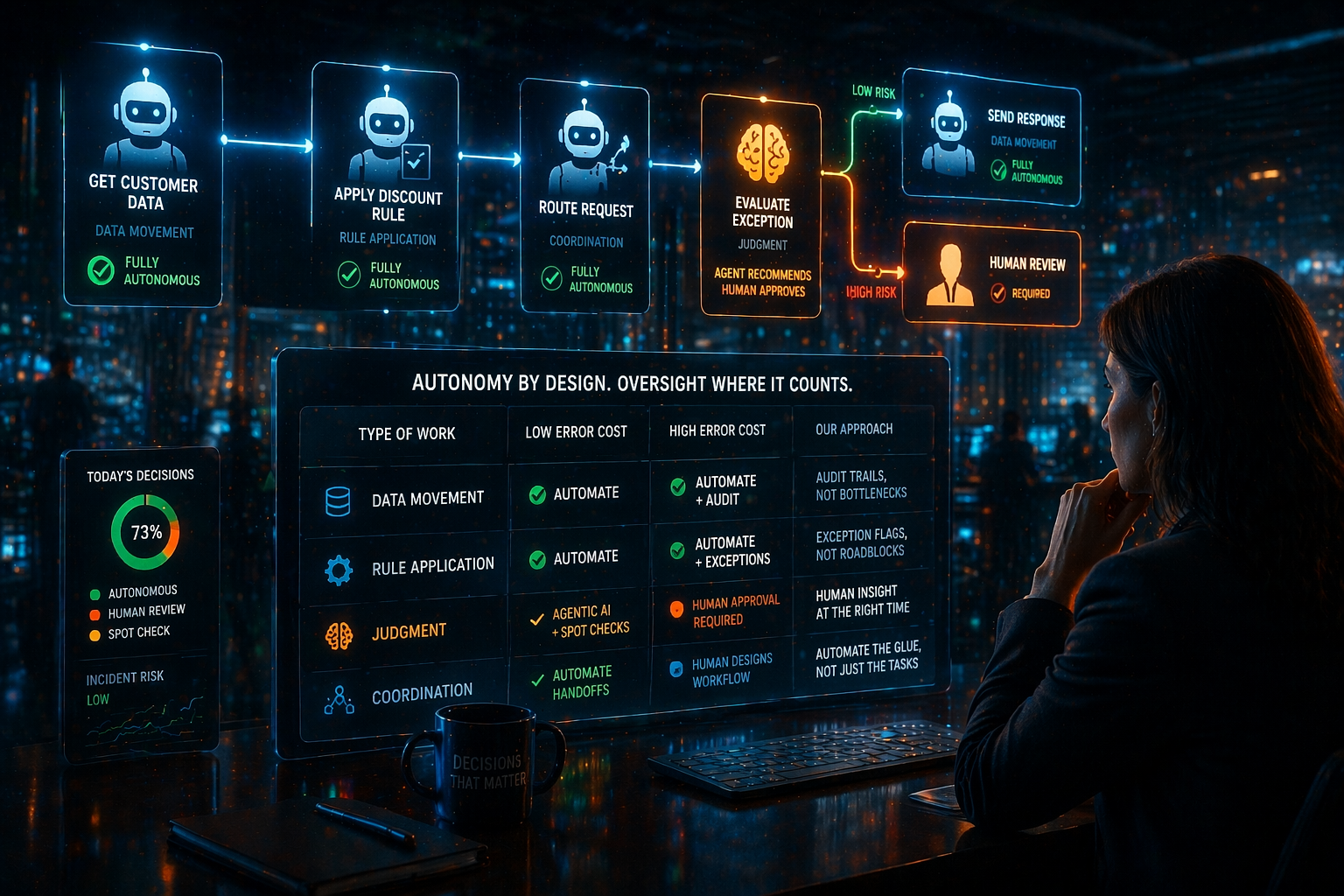
The Classification That Helps
There’s a simple way to map this. Take the actions your agent performs, not the agent itself, and sort each one across two dimensions: the type of work and the cost of getting it wrong. This only works if you know what’s running and what those agents can actually reach. If you haven’t done the inventory work yet, Part 2 of this series is the right starting point. And if you’re not sure how agents are connecting to enterprise data, The Agent Can Think. It Just Can’t Get to the Data. covers the connectivity layer.
Start with coordination, because it’s where most organizations leave value on the table. Coordination means managing handoffs between systems, teams, or other agents. Most people instinctively look for automation value in task execution. But the bigger opportunity is usually in collapsing the overhead between tasks. An agent that removes a five-step handoff between three teams delivers more value than an agent that speeds up one of those steps. The leverage is in the glue, not the parts. And because coordination actions are often lower-risk individually, they’re also easier to automate without adding human review overhead.
The other three categories do most of the remaining work:
Data movement. Retrieving, transforming, or routing information. Pulling a record from a CRM, appending a log entry, syncing a field. Deterministic when the schema is clean.
Rule application. Executing defined logic against known inputs. Classifying a ticket, routing a request, applying a discount threshold. Predictable when the rules are well-defined.
Judgment. Making a call where the policy doesn’t fully cover the situation. Drafting a response to an ambiguous customer complaint, deciding whether an exception is warranted, interpreting context the rules weren’t written for. This is where human oversight earns its place, and it connects directly to the identity and scoping work from Part 3. Identity defines what an agent can access. Guardrails define which of those things it acts on autonomously.
Crossed with cost of error, low or high, this gives you a working classification for each action in a workflow.
Data movement with low error cost: automate it fully, check the audit trail periodically. Rule application with low error cost: same. Judgment with high error cost: the agent can prepare and propose, but a human approves before anything executes.
One caution before you use this: some actions look deterministic on the surface but carry high systemic risk when executed at scale. An agent that applies a pricing rule correctly 99.9% of the time will still misfire on hundreds of transactions if it’s running volume. The classification isn’t just about the action type. It’s about what happens when that action type runs at the speed and scale agents actually operate at.
When the Classification Isn’t Enough
The framework handles most agent actions well. But some workflows live in territory that isn’t cleanly classifiable, and it’s worth knowing the difference.
The easiest case: genuinely simple problems where cause and effect are clear and best practice exists. The agent should just execute. Don’t add human review here out of habit. It creates overhead without adding safety.
A step up from that: complicated problems that are knowable with expertise. The logic can be captured in rules, there are multiple valid approaches, and agentic AI with good business rules works well. Route exceptions to humans when the agent hits a case outside its decision envelope… but not before.
The hard one is genuinely complex problems. Situations where you only understand what happened in retrospect, where novel factors change the picture, where the right answer isn’t derivable from past experience. Human judgment is integral here, not a bottleneck. The human isn’t slowing the agent down. The human is part of how good decisions get made at all.
The mistake most organizations make is treating complex problems as though they’re merely complicated. They write rules for situations that don’t have rules. They automate decisions that require genuine judgment. And then they wonder why the agent keeps producing outputs that are technically correct and operationally wrong.
If you’re seeing that pattern… an agent doing exactly what it was told and still creating problems… that’s usually a sign you’ve applied the wrong autonomy model to the wrong domain.
Policy That Actually Enforces Itself
Here’s the part that most governance conversations skip.
Organizations have policies. Most have plenty. The problem is that policies live in documents nobody reads, and agents make decisions at machine speed without consulting documents. A policy that says “high-risk actions require human approval” means nothing if the system doesn’t know which actions are high-risk and doesn’t stop to ask.
The classification work above only matters if it becomes operational. The oversight level for each action category needs to be encoded into the system itself, not written down somewhere. Before an action executes, the system evaluates: what type of action is this, what’s the risk tier, what does the policy say? Auto-approve for low-risk deterministic actions. Route to a reviewer for high-judgment high-stakes actions. Block for anything outside defined scope.
Documents don’t enforce themselves. Agents act at machine speed. The oversight logic has to live in the runtime, not in a Confluence page.
What This Actually Looks Like in Practice
The first version of this is not a platform. It’s a working session.
Get the workflow owner in the room. Break one live agent workflow into its actual actions, not the architecture diagram, the real things the agent does step by step. Classify each action quickly using the framework above. Then argue about the two or three where the risk isn’t obvious. That argument is the point. The places where reasonable people disagree about the risk level are exactly where the autonomy default is most likely to be wrong.
I’d start with one workflow, not the whole estate. I wouldn’t try to classify every agent in the organization on day one. I’d pick the workflow where something has already felt off… where a human has had to clean up an agent’s output more than once, or where the team instinctively added a review step without ever formalizing why. That’s usually where the autonomy level is most misaligned with the actual risk.
The first pass will be wrong in places. That’s expected. The useful signal comes from production. Look at where humans are reviewing too much, which usually means the action is over-tiered and the policy is creating unnecessary overhead. And look at where things are being caught too late, after the action has already executed, which means the action is under-tiered and the oversight is happening after the damage is done.
Both signals tell you where to recalibrate. The goal isn’t a perfect first-pass classification. It’s a living policy that gets smarter as the system shows you where the autonomy model is right and where it isn’t.
The Question Worth Asking Now
Which of your agent actions are running fully autonomously right now… and did anyone deliberately decide that, or did it happen by default?
What’s Next
Risk tiering tells you which agent actions need a human and which ones don’t. But that’s a point-in-time decision. Between reviews, how do you know whether the agents are still behaving the way the policy assumed they would?
An agent that was correctly classified at deployment can drift… not because someone changed the agent, but because the world it operates in changed. New data patterns. New edge cases. New volume levels the original logic wasn’t tested at. The policy says it’s safe to automate. Is it still?
That’s posture management. That’s Part 5.
Managing the Digital Workforce | Part 4