
At scale, humans can’t review every agent interaction. The answer to that problem is going to make some people uncomfortable.
The Breaking Point
Up to this point, the governance model has been clear. You define the agents. You assign identity. You enforce guardrails. You monitor posture. And somewhere in that system, a human remains accountable.
That works… until it doesn’t.
The moment you move from a handful of agents to dozens, or hundreds, the idea that a human can meaningfully review every interaction doesn’t just become difficult. It collapses operationally. Not in theory. In practice, in the daily reality of a production environment running at scale.
When that happens, you don’t get better oversight. You get one of two outcomes: superficial review where humans are rubber-stamping outputs they don’t have time to fully validate, or no review at all where systems run unchecked between audits. Neither is acceptable. Both are more common than anyone wants to admit.
So the question becomes: what sits between human checkpoints?
What a Guardian Agent Actually Is
Before getting into the argument, it’s worth grounding the concept, because “guardian agent” is showing up in a lot of vendor conversations right now and the term is getting used loosely.
The framing that matters most for enterprise leaders isn’t architectural. It’s institutional. A March 2026 article in the California Management Review made the point precisely: autonomous AI agents have transitioned from tools to actors. When a spreadsheet produces an error, responsibility lies with the analyst who used it. When an autonomous agent approves a transaction or reroutes a shipment, responsibility is often ambiguous. Guardian agents are part of the answer to that accountability problem, not just a technical control.
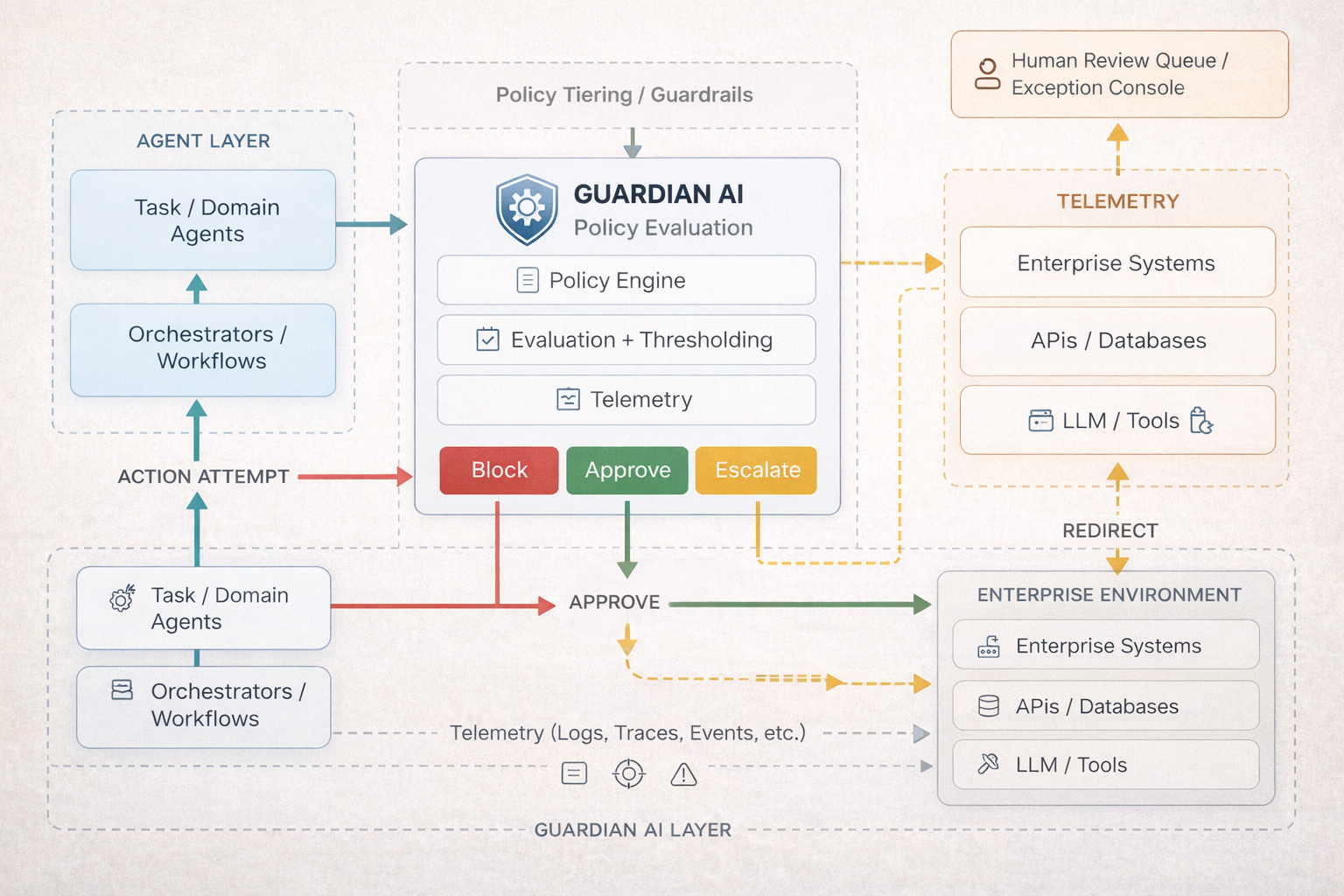
Architecturally, a guardian agent is a purpose-built system whose job is to watch other agents operate, not to do the work those agents do. Not an orchestrator. Not a generator. An observer with enforcement capability. The governance logic sits in a separate layer from the agents being governed, so you can change what the guardian enforces without touching the underlying workflows. In practice, effective deployments combine rule-based policy enforcement for hard boundaries with behavioral monitoring for drift and anomalies. Rules cover what you anticipated. Behavioral baselines catch what you didn’t. Both are necessary.
Gartner formally recognized the category in February 2026. This is no longer a fringe pattern. It’s becoming a category.
A Real Example
I’ve implemented this pattern in a high-volume document processing pipeline. The context: structured summaries generated from complex source documents, where precision in both format and content is non-negotiable. Every summary needs to be evaluated against the source material. Every section needs to be complete. Every deviation from expected patterns needs to be caught.
Historically, that validation took hours per document. A human reviewer would check structure, completeness, alignment to source material, and whether anything had been introduced, omitted, or misrepresented. That level of review is necessary. It’s also not scalable when you’re processing volume.
So we changed where the oversight lives, not whether it exists.
A QA agent now evaluates every summary the pipeline produces. It doesn’t skim. It scores structure and completeness, verifies alignment to source material, detects deviations from expected patterns, and produces a pass/fail decision with a confidence score and a scorecard explaining the result. Most importantly, it determines when a human needs to get involved.
The human review didn’t disappear. It got more targeted. Instead of reviewing everything superficially, reviewers are looking at the cases the QA agent flagged, with context about exactly what triggered the flag. The signal-to-noise ratio is completely different.
The Objection You’re Already Thinking
If AI is overseeing AI, haven’t you just moved the problem?
It’s the right question. And the answer is no, but the reasoning matters.
The QA agent isn’t doing the same job as the system it’s evaluating. The generative pipeline is interpretive, judgment-heavy, operating in territory where context and nuance shape every output. The QA agent isn’t. Its job is narrow and explicit: enforce structure, verify consistency, detect deviations, measure confidence against defined thresholds. It’s not trying to understand the case. It’s trying to answer a much simpler question: did the system behave the way it was supposed to?
That distinction matters. A lot.
A narrowly scoped oversight function operating against defined criteria is a fundamentally different problem than open-ended generation operating against complex real-world inputs. The failure modes are different. The risk surface is different. The ability to validate the validator is different.
This is the same logic that makes security operations centers viable. No one expects analysts to manually review every log, every event, every network signal. Detection systems monitor continuously, surface anomalies, and escalate what matters. Humans investigate and decide. The detection layer doesn’t replace human judgment. It makes human judgment sustainable at scale. Guardian agents follow the same pattern.
The Guardian Agent Layer in the Stack
This is the next layer in the governance architecture. Not orchestrators that coordinate work. Not generators that produce outputs. Observers that watch other agents operate.
Guardian agents exist to enforce boundaries. In practice that means monitoring for policy violations, scope creep, behavioral anomalies, confidence breakdowns, and cost and usage thresholds. When something crosses a defined boundary, they escalate. Not everything. Only what matters.
To make it concrete: imagine a Procurement Agent whose behavioral baseline is $10,000 suddenly initiating a $50,000 payment. A guardian intercepts it, checks whether the agent’s confidence score meets the threshold for autonomous action, and if not, blocks it and routes it for human review. The human didn’t watch every transaction. They reviewed the one that needed them. That’s the model.
The behavioral monitoring piece works the same way. An agent whose job is scheduling meetings that suddenly starts executing shell scripts isn’t violating a static rule. It’s operating outside its intended behavioral envelope entirely. A guardian watching for that kind of scope departure catches it whether or not anyone wrote a rule to cover it specifically.
The key design principle remains the same: guardian agents don’t make final decisions on consequential outcomes. They flag them. They route them. They provide context in the form of confidence signals and structured findings. The human still decides. But they’re deciding on cases the system has identified as worth their attention, with the information they need to decide well, rather than reviewing everything at a pace that makes real review impossible.
This connects back to Part 5. Posture management monitors whether an agent’s configuration has drifted from what was originally approved. Guardian agents monitor whether an agent’s behavior has drifted from what’s expected in real time. The two layers are complementary. Configuration tells you the agent is set up correctly. Behavioral oversight tells you it’s actually operating correctly, right now, at the action level.
Closing the Loop on the Stack
This is where the governance stack starts to close on itself.
The registry defines what exists. Identity defines who can act. Guardrails define what’s allowed. Posture management defines how systems are configured over time. Guardian agents define what happens when all of that runs at a scale no human team can monitor directly.
None of the earlier layers hold at scale without this one. A registry without continuous oversight is a list. Guardrails without enforcement are aspirational. Posture management without behavioral monitoring catches configuration drift but misses operational drift. The governance stack only functions as a stack when every layer is operational.
Guardian agents are how accountability works at machine speed.
Who Guards the Guardians?
There’s a harder question underneath all of this that most vendor conversations don’t surface. If guardian agents are themselves AI systems, what governs them?
It’s not rhetorical. Guardian agents are built on the same foundation models as the agents they monitor. If your guardian platform and your production agents both run on the same underlying model, there’s a legitimate question about whether the guardian has a native blind spot for that model’s failure modes. The vendor space hasn’t answered this cleanly.
There’s also a conflict of interest problem. The organizations best positioned to sell you a guardian agent are often the same ones selling you the agents being guarded. A company with a financial incentive to show its agents performing well may not be the most credible source of oversight for those same agents. That conflict doesn’t make the tools worthless. It makes vendor-neutrality a procurement requirement, not a nice-to-have.
Three questions worth putting directly to any guardian vendor: Is it vendor-neutral, capable of monitoring agents across all platforms without favoring its own ecosystem? Is it built on different foundation models than the agents it monitors? And does the organization providing it have a financial interest in the performance narrative of the agents being watched?
These aren’t reasons to avoid the model. They’re reasons to implement it deliberately.
The Real Tradeoff
Some organizations will reject this model because the idea of AI validating AI feels like a loss of control. That reaction is understandable. But it’s worth being honest about what the alternative actually is.
At scale, you’re not choosing between AI oversight and human oversight. You’re choosing between AI oversight and the illusion of human oversight. A human review process that touches 2% of interactions at a pace that makes real scrutiny impossible isn’t oversight. It’s a liability with paperwork.
Guardian agents aren’t a philosophical shift. They’re an operational response to a real constraint. And in most environments running meaningful agent volume, some version of them is already operating, whether they were designed deliberately or assembled from monitoring tools, alerting systems, and exception queues nobody fully connected.
The question isn’t whether AI will watch AI in your environment. At scale it already is, in one form or another. The question is whether you designed it to do that job well, or whether it happened by accident.
The Question Worth Asking Now
Do you know which of your agent interactions are being reviewed by a human today… and which ones aren’t? And for the ones that aren’t, what’s actually watching?
What’s Next
Guardian agents solve the coverage problem. But every agent in the stack, including guardian agents, still needs a chokepoint. A single place where all agent traffic flows, where policy is enforced, where access is controlled, and where the audit trail is built.
That’s an agent gateway. And it’s the layer that makes everything else auditable.
That’s Part 7.
Managing the Digital Workforce | Part 6