
Five platforms. Five security models. Five ways to access your data. Five places where an agent could go wrong. You’re not even trying to run a heterogeneous fleet — it just happened.
The Problem Nobody Meant to Create
Your developers are using Claude Code in their terminals. Your product team built a customer success bot on Writer. Marketing runs campaigns through a GPT they configured in ChatGPT Enterprise. Sales uses Microsoft Copilot. And someone in ops — you’re not sure who — stood up an internal agent that pulls from the CRM.
That’s five platforms. Five security models. Five ways to access your data. Five places where an agent could go wrong.
You’re not even trying to run a heterogeneous fleet. It just happened.
The Pattern Isn’t New
This isn’t the first time enterprises faced this problem.
In the mid-1990s, IT ran equipment from dozens of vendors. Sun servers, Cisco switches, EMC storage arrays, HP printers. Different management consoles. Different monitoring tools. Different ways to authenticate, audit, and kill a connection when something went sideways.
The answer wasn’t “standardize on one vendor.” The answer was a control plane — systems like HP OpenView, IBM Tivoli, and later CA Unicenter that sat above the vendor chaos and gave IT a single pane of glass. One place to see what was running. One place to enforce policy. One place to pull the plug.
That pattern — the single architectural chokepoint — became foundational infrastructure. SIEM platforms did it for security events (Splunk, ArcSight). Service management platforms did it for incidents (ServiceNow, Remedy). API gateways did it for microservices (Kong, Apigee).
The same pattern is forming again. This time for agents.
Why This Matters
Your board doesn’t care about gateway architectures. But they will eventually care about three things.
Liability. If an agent leaks customer data or makes a decision that costs you money, can you prove you had reasonable controls in place? “We didn’t know that agent was running” is not a defense. “We couldn’t stop it fast enough” is worse.
Trust. Can you tell customers and regulators that you know what your AI is doing? Without a chokepoint, your answer is “we think so” or “we’re working on it.” Enterprise customers and auditors hear that as “no.”
Speed. Are your AI governance controls going to become a bottleneck that slows down every team that wants to deploy an agent? Without a chokepoint, every new agent requires custom security review, custom audit trail setup, custom access controls. Teams either wait months for approvals or route around IT entirely… which circles back to liability.
The chokepoint doesn’t eliminate these risks. But it makes them answerable.
What the Chokepoint Actually Does
The agent gateway sits between your applications and the AI models they call. All agent traffic — requests, responses, tool invocations — flows through it.
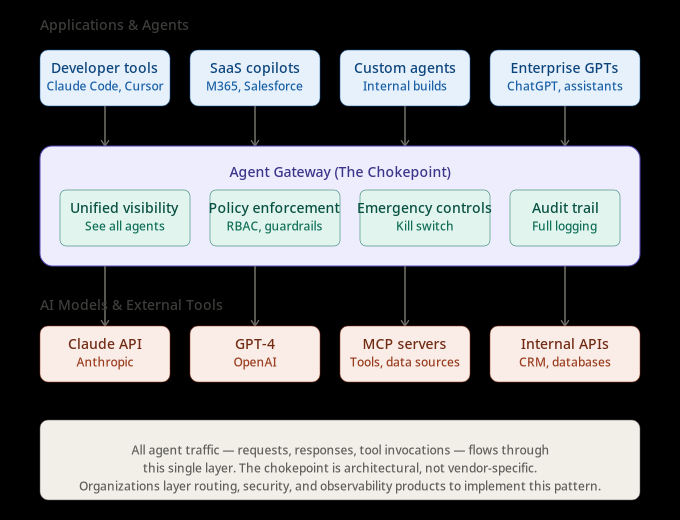
The agent gateway as a single architectural layer. Applications and agents route through one control point before reaching AI models and external tools.
That position creates four capabilities you can’t get any other way.
Unified visibility. One place to see all agents, regardless of where they run. Developer tools like Claude Code and Cursor, SaaS copilots like Microsoft 365 and Salesforce Agentforce, custom agents your teams built — they all route through the same layer. You can answer “what agents are running” without hunting through five admin panels.
Policy enforcement. Role-based access controls. Tool access restrictions. Rate limits. Content guardrails. All enforced at the gateway, not configured separately across platforms. An agent approved for customer support can’t suddenly access the finance database because the policy lives in one place.
Emergency controls. It’s 4:47 PM on a Friday. Security just flagged an agent exfiltrating customer PII to an external API. If you have a chokepoint, you revoke the agent’s credentials in one place. Policy propagates. The agent stops. If you don’t, you’re hunting through settings panels across five platforms, hoping you found everything before the next API call completes.
Audit trail. Compliance requires reconstructing what happened. The gateway logs every request, every tool invocation, every response. When regulators ask “what did your AI do on March 15th and why,” you query one system. The alternative is stitching together logs from multiple platforms, assuming they all kept logs, assuming the timestamps align, assuming nothing got purged.
This Isn’t One Vendor’s Problem to Solve
Organizations aren’t picking one vendor that does everything. They’re layering infrastructure.
The most sophisticated deployments separate concerns: prompt-level filtering (injection detection, PII redaction), tool-level access control (which agents can invoke which APIs), and output-level validation (content filtering, hallucination detection). A routing gateway optimized for multi-provider failover isn’t built for runtime threat detection. A security platform purpose-built for agent posture management doesn’t handle semantic caching.
This isn’t because the market is immature. It’s because specialized depth beats generalist breadth. The chokepoint is an architectural pattern, not a single product. Traffic flows through common layers, but those layers are often operated by different vendors.
The Pattern Is Converging
When multiple standards bodies form around the same infrastructure pattern within six months, that’s not hype. That’s consensus.
The Model Context Protocol went from zero to 97 million monthly SDK downloads in 16 months. Every major AI provider now supports it — Anthropic launched it, OpenAI adopted it in April 2025, Microsoft integrated it into Copilot Studio by July, AWS Bedrock added support in November. In December 2025, Anthropic donated MCP to the Linux Foundation under the newly formed Agentic AI Foundation.
Standards bodies don’t form around hypothetical problems. They form around infrastructure that’s already being deployed at scale and needs interoperability.
The OpenTelemetry project (a CNCF initiative) released GenAI Semantic Conventions in version 1.37, standardizing how agent observability works across frameworks and vendors. When Datadog announced native support in February 2026, that signaled the standard had reached production adoption. Organizations building new observability infrastructure can now default to OpenTelemetry rather than vendor-specific telemetry formats.
Kubernetes launched an AI Gateway Working Group in March 2026 to standardize network-layer controls for AI workloads — payload processing for prompt injection detection, egress gateways for secure routing to cloud AI services, regional compliance enforcement.
ServiceNow announced a native integration with Zenity at RSA Conference in March 2026. Agent discovery, security posture management, and runtime threat detection now surface directly in ServiceNow SecOps workflows. Organizations already running ServiceNow for IT service management can extend the same patterns to AI agent governance.
The pattern is repeating across the industry. The chokepoint isn’t a single vendor’s vision. It’s becoming the architectural consensus.
What to Do About It
If you’re just waking up to this, start here.
Map what’s running. You can’t govern what you can’t see. Inventory agents across SaaS platforms, cloud environments, and developer endpoints. Most organizations discover they have 2-3x more agents than IT thought.
Pick your routing layer. The decision criteria matter more than the vendor. Does it support the Model Context Protocol? Can it enforce role-based access controls? Does it generate audit logs you can actually query? Can you test the kill switch — revoking access to a specific data source in under 60 seconds?
Layer security on top. AI Security Posture Management evaluates agent configurations before runtime — permissions, memory access, tool integrations. Runtime detection monitors for prompt injection, data exfiltration, and tool misuse during execution. These are typically separate products from your routing layer, and that’s fine. Specialized depth beats generalist breadth.
Instrument for observability. The OpenTelemetry GenAI semantic conventions provide a vendor-neutral way to emit spans, metrics, and events from agent operations. Frameworks like CrewAI have native support. Others require external instrumentation libraries. Either way, standardized telemetry means you can swap observability backends without rewriting instrumentation.
If you’re already running gateways, audit coverage. Are all agents routing through it, or just the ones IT knows about? Test the kill switch. Can you revoke access to a data source from the gateway in under 60 seconds? Use discovery tooling to find shadow agents — the ones running outside your chokepoint.
The window to build this proactively is closing. The EU AI Act becomes fully applicable in August 2026, with compliance obligations phasing in over the following months. Gartner projects 40% of enterprise applications will include agents by end of 2026. You’re not choosing whether to govern agents. You’re choosing whether to do it before or after the first incident.
What Comes Next
The gateway gives you the chokepoint. Everything flows through one layer. You can see it. You can control it. You can stop it.
But that only matters if someone can reconstruct what happened when something goes wrong. The audit trail the gateway generates is worthless if you can’t prove who authorized what, why the agent did what it did, and whether the outcome was the one you intended.
That’s the next layer. The one regulators care about most.
That’s Part 8.
Managing the Digital Workforce | Part 7