Building an Empire of Knowledge with Semantic Data
It seems like every crime show includes a few scenes where we see that the detective has built a wall of pictures, newspaper clippings…
It seems like every crime show includes a few scenes where we see that the detective has built a wall of pictures, newspaper clippings, index cards and other interesting documents, linking all these things together through a network of string and push pins. This linked data allows them to step back and see how the facts relate and helps provide the bigger picture of what happened and how to solve it. Seeing the bigger picture allows detectives to use inductive and deductive reasoning to pursue leads,identify gaps in their knowledge and continue the investigation in ways they may not have seen before.
The crime wall is a physical representation of knowledge or context. The crime wall helps investigators see the relationships and understand the true meaning of the facts surrounding a case. Understanding context can lead to accelerated insights and increase the productivity of the detectives. In the digital world, we can represent knowledge through similar techniques. We call this digital representation a knowledge graph.
Just like detectives, the autonomous enterprise of the future and the digital workers that will run them, will need rich contextual data, also known as semantic data. The true power and value of digital transformation will only be unlocked by the adoption of a semantic data-driven approach. The future of work will be built on digital workers powered by machine learning, artificial intelligence and fueled by knowledge graphs and semantic data. It’s not enough for an organization to be “data-driven” anymore. They need to become contextually-driven for true insights and process acceleration.
The Semantic Web
The Semantic Web vision was first presented by Sir Tim Berners-Lee in 1994 at the first World Wide Web Conference and later made popular by an article in Scientific American in May 2001. Semantics is the linguistic and philosophical study of meaning. The new vision promised a new type of meaningful and connected information that could be processed by systems and machines would unleash a wide range of possibilities. This new web of structured data would allow intelligent agents to operate on our behalf. This Semantic Web would provide the context to power a new generation of innovation and automation.
Unfortunately, the Semantic Web has yet to live up to the promise of its vision. Nearly 20 years later, agents have yet to provide significant productivity gains. Most enterprises don’t have anything close to being a Semantic Web and the closest things we have to intelligent agents are Siri and Alexa. So why hasn’t the Semantic Web taken off?
The basic idea behind the Semantic Web was that everyone would use a new set of standards to annotate their webpages with little bits of metadata. These little bits of metadata could be read by software programs to divine meaning that otherwise would only be available to humans. The goal was to start capturing the meaning, relationships and context that was frequently stripped away when information was captured and stored.
Create Value or Blame the System
Some people blame technology approaches for the delay. Some people might cite all the new standards that needed (and still need) to be developed. Others might point fingers at the lack of tools and support to make it happen. I’d argue that it was the lack of a compelling business event or value proposition.
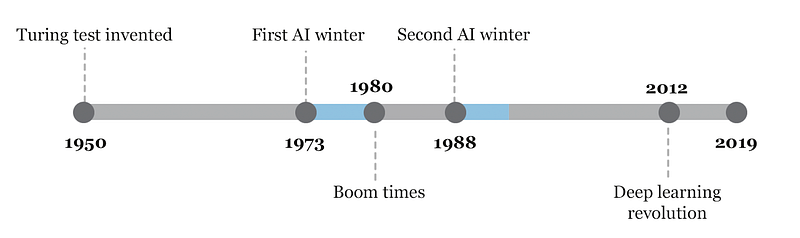
Only recently have we seen the rise of the digital assistants and bots powered by AI technologies. The simple truth is that the code or core technique behind AI hasn’t changed for decades. There have been no fundamental breakthroughs or significant innovations. We’ve been in a bit of an AI winter with frozen code, until recently. Over the last 5 years or so, we’ve seen a significant advancement in the computational power of devices, which now allow us to process the data fast enough to make the algorithms feasible in real-world scenarios.
https://www.researchgate.net/figure/Timeline-of-the-AI-winters_fig1_333039347
What has changed is organizations now have access to near limitless compute and storage via cloud services providers like AWS and Microsoft Azure. The infrastructure required to run AI in the enterprise, that would have been cost prohibitive before, can now be purchased on demand with no impact to an organization’s capital expenditure. As a result, we have a business environment where intelligent agents can be built, deployed and operated at scale to drive real value and power automation and productivity initiatives. However, we lack the context needed to power the enterprise Semantic Web.
Some good things have materialized over the last few years despite many believing the Semantic Web was dead along with all the resulting misconceptions and misunderstandings. While it no longer shows up on the Gartner’s Hype Cycle, if you take a look at the 2019 Hype Cycle for Emerging Technologies, you’ll see the influence of Semantic Web and enabling technologies like RDF, graph databases and knowledge graphs.
Building the “Crime Wall” for the Enterprise
An enterprise knowledge graph provides a representation of an organization’s knowledge, domain and artifacts that is understood by both humans and machines. Knowledge Graphs allow us to represent the context with high accuracy, understandability and most importantly reuse. Once a knowledge graph is created, it can continue to scale and connect more information and data to build a complete understanding of the entire set of data. Enterprise knowledge graphs are like a digital version of the detectives crime wall.
Enterprise knowledge graphs allow organizations to:
- Discover facts hidden in the data and predict future outcomes or events
- Determine which products or services are most profitable and perform better
- Predict breakdown or service failure of products and systems
- Enable employees and systems to query knowledge across structure types and silos
- Support and lay the groundwork for automation and AI initiatives
Building enterprise knowledge graphs can be broken down into four key activities:
Step 1: Identifying the Problem or Case to Solve
Determining which processes or business functions could benefit the most from a semantic approach to automation should not be taken lightly. As an organization undergoes digital transformations and pursues automation projects, they will quickly find that their efforts are usually competing for the same resources. Identifying a solid use case becomes critical for securing the necessary buy-in and support from the organization.
There are a number of approaches that organizations must consider when pursuing automation and productivity projects. An organization could focus on smaller and simpler tasks that can allow the company or team to learn and get some quick wins. Another approach would be to focus on larger processes where the rules are well known and have a higher probability of success. By taking a semantic approach and leveraging knowledge graphs, organizations can embrace a more data-driven approach to selecting opportunities. By leveraging knowledge graphs organizations can focus on processes that might have been impossible to automate previously such as:
- Tasks or processes that might require searching using natural language
- Dynamically querying and gathering data from disparate data silos
- Processes that evolve and change based on the context and business environment
Once the use cases have been identified, prioritized and selected, we can move onto defining the semantic model and curating the context needed to fuel the project.
Step 2: Defining the Taskonomy
The second step in applying a semantic approach to automation and productivity is moving beyond the documents and understanding the contextual data relevant to a particular process or task. If we were to create a model of the context surrounding this process or task, the result would be what we call a taskonomy. A taskonomy is a model of all the context and data a worker, either human or digital, would need to perform a specific task or execute a particular process.
A taskonomy describes and organizes the data around a specific task or process in an effort to provide the worker all the contextually relevant knowledge they need to perform the task or automate a process. Developing a business taskonomy provides structure to unstructured information and ensures that an organization can effectively capture, manage and derive meaning from large amounts of data.
By defining the taskonomy and organizing the data in this way provides us a stepping stone to allow the next phase of mapping relationships, linking disparate data and ultimately producing context to power both human and digital workers.
Step 3: Enriching and Linking Data
Once we have the taskonomy, or a semantic model representing the task or process needed to automate and have identified data relationships, we can begin to turn our flat data (data that has no meaning, links or relationships) into contextual or semantic data.
This is where we use machine learning to extract and curate data from unstructured and semi-structured data while ignoring the data that is not integral to the task. In this step, we do things like classify data and use deep learning to recognize and extract entities from flat data.
Leveraging the power of the taskonomy to define the entities, relationships, connection for our use case provide the model for capturing the context and a map for creating the knowledge graph.
Step 4: Build a Knowledge Graph
It’s important to resist the urge to start big and instead focus on small meaningful knowledge graphs that evolve and grow over time. Create a small pilot based on the select use case taskonomy and the data available. Test the knowledge graph against the use case to validate the model, data and value. Taking an iterative approach to fine tuning the taskonomy, gathering and linking additional data, and building the knowledge graph will allow organizations to gain perspective and deliver incremental value before increasing investments.
Better Outcomes Result from Semantic Data
Digital transformation, cross-silo data validation and ultimately full, end-to-end process automation can only be unlocked by the adoption of a semantic data-driven approach. Organizations that continue to pursue these outcomes using the flat data systems of the past will only be met with defeat. The autonomous enterprise of the future, and the systems that run them, will be fueled by rich, contextual data. Enterprise knowledge graphs will play a key role in achieving true productivity and be companies who want to lead the market, not follow. It’s time to start building your empire of knowledge.


